I had the honor to attend the “Machine Readable Rights Workshop” at the IPTC Autumn 2014 meeting in Frankfurt, Germany today. And to hold a short presentation [PDF] on “Rights Management in the DC-X DAM”. Here’s what I intended to say (the actual talk was a bit shorter):

“I’ve been following the IPTC’s work for many years and I think you’re doing a great job, and you keep changing the news industry for the better. Thanks for that! And I’m also excited to meet some of the people I follow on Twitter in real life. Thanks a lot for the invitation to this workshop!
Digital Collections is a rather small DAM system vendor, but has lots of experience in the publishing industry. 23 years ago, we were one of the first companies in the world to build digital newspaper archives, and to import digital text and photos from news agencies into a full-text searchable database.

Our product DC-X is a pretty normal DAM system: It provides a database and search engine, at which you can throw any kind of file or text. Our customers usually keep their editorial newspaper or magazine content in it, and input from news agencies and photographers: Images, videos, article text, PDF pages and so on. The largest installations store tens of millions of documents and receive tens of thousands images per day. We extract text and metadata, and make it searchable and editable. And then we’re integrating that with other software: editorial systems, Web CMS, syndication and so on. Our customers are calling DC-X their “content hub”.

I have to admit that I haven’t heard our customers ask for RightsML support so far. I’d love to play with RightsML, but that’s why we haven’t started work on an implementation yet. But I really hope this is going to change, and maybe you can provide me with some selling points today.

But what our customers are asking for is rights management inside our application. They need to know whether they’re allowed to use an image online – or in new output channels, like an app. Costs are important, too; expensive images need to be marked as such. And customers who open up their historical newspaper archives might have to set rights for old content.

We started working on that feature four years ago, and maybe a third or half of our customers have already started using it. We’re focusing on what we call “rights profiles”, which is a set of rights metadata that is identical for multiple digital assets. We’re trying to model the actual contract between a content provider and the content user in a rights profile.
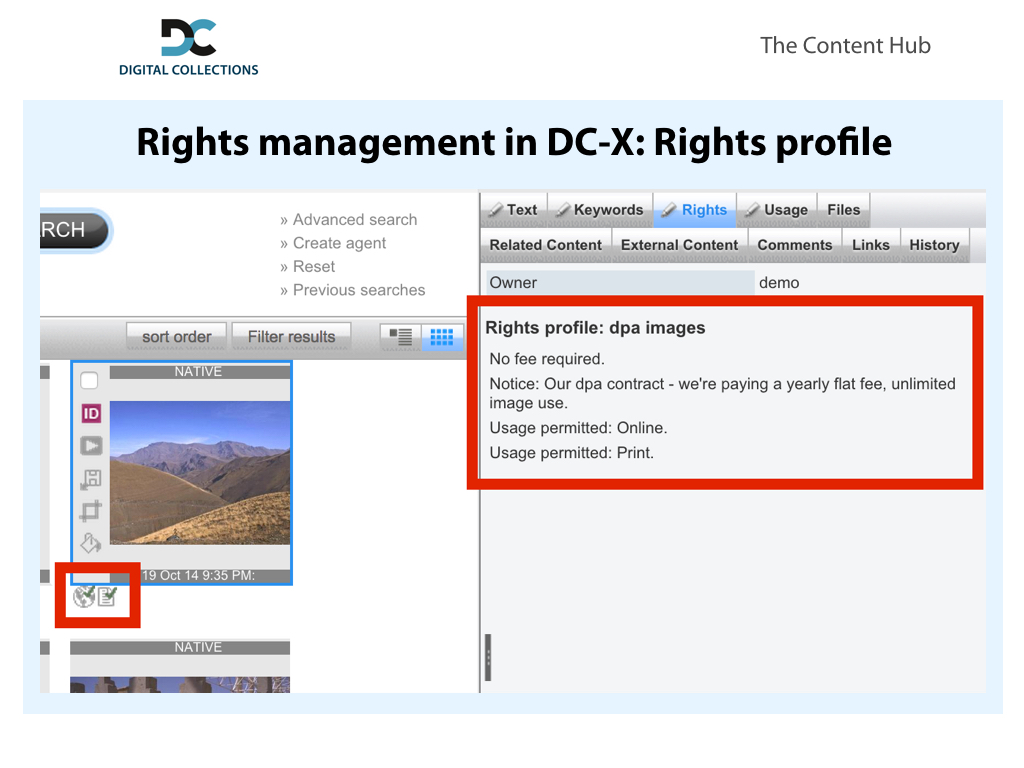
For example, there’s a contract between a newspaper publisher and the German news agency dpa that permits the newspaper to use images online and in print without paying royalties per image (covered by a yearly fee). One contract means one rights profile in our software, which is linked to the thousands of images from the dpa within the DAM. We’re storing the rights metadata in a structured, machine readable way. You can see a textual description on the right hand, and two icons below the image that mean “Online usage OK” and “Print usage OK”.

Then there are rights that are valid only for a single image – we’re calling these “special agreements”. Special agreements take precedence over rights profiles. So when the news agency revokes an image, you don’t have to remove the rights profile for the general contract – you add a special agreement for that image, whose properties then selectively override the rights profile’s. In the screenshot, you can see me adding a special agreement with “Usage permitted: None”.

Look how the print and online usage are now grayed out, and a red warning sign is displayed.

The rights metadata form can be customized, of course. Here’s a complex real-life example.

Now how could RightsML help us? One of the biggest hurdles for our customers to adopt our rights management features is that they have to manually define all these rights profiles, and configure our software to link to the correct rights profile on import. That’s a lot of work. It would be great if content providers could do that work instead and provide the correct rights profile. But because we have built our own proprietary and simplistic rights engine, we’re stuck. Implementing RightsML would enable interoperability.
Two more things I’m currently thinking about with regards to RightsML:

First: The spec says that RightsML need not be embedded, it can be “communicated separately”. That seems to be an attractive option for a couple of use cases: A) When many content items share the same rights. We don’t want to store the same set of rights again and again for each item. Not just to save space, but to make it easier to edit rights in our system. And B) we often have images in our systems that must be bought before they can be used, and the exact rights are being negotiated on the phone or during an online purchasing process when the image file is already in the production process.

And the second thing: In my eyes, rights are pretty different from other kinds of metadata. And the data structures and algorithms for storing and evaluating RightsML or PLUS expressions are complex and hard to implement. It starts with having to create several database tables just to store the rules. I don’t see too many software vendors doing a proper implementation soon.

But that rights are so different, and essentially independent of the content, is also an opportunity: It allows us to handle rights outside of the existing applications. Ideally, there would be an application that specializes in displaying, editing and evaluating machine readable rights. A Web CMS or DAM could call its API to store or retrieve rights, and to evaluate whether a specific usage is allowed. Later you could add contract, usage and royalties information. (A part of that functionality seems to be covered by the PLUS Registry, by the way. But personally, I’d favor a local registry over a central one – I’m not sure about performance and security, and we’d want to use the registry for article text as well which isn’t the PLUS use case.) I’m convinced that open source, easily-integrated “machine readable rights hub” software would help drive RightsML adoption.

I’m looking forward to the discussion. Thanks for your time!”
Update: See my follow-up post The business case for machine readable rights.